
Unsloth Studioは、オープンモデルの実行、データ準備、学習、書き出しをブラウザ画面から操作できるWeb UIです。2026年6月13日時点では、macOS、Linux、WSL、Windows向けのワンライン導入が公式に案内されています。
この記事では、Unsloth Studioの使い方を、StudioとCoreの違い、必要環境、最短の開始手順、モデル選び、メモリ不足時の確認、安全な公開方法の順で説明します。
Unsloth Studioとは
Unslothは、オープンモデルをローカルで実行したり、学習したりするためのプロジェクトです。GitHubの説明では、Unsloth StudioがWeb UIとして提供され、Gemma 4、Qwen3.6、DeepSeek、gpt-ossのようなオープンモデルをローカルで扱えることが示されています。初心者にとって大きいのは、「コマンドだけで全部を操作する」のではなく、Web UIという見える画面を通して、モデルの実行や学習に取り組める点です。
GitHub上のREADMEでは、Unsloth StudioはWindows、Linux、WSL、macOSで動作すると説明されています。また、テキストだけでなく、音声、埋め込み、ビジョン系モデルにも触れられており、単なるチャット実行ツールにとどまらない構成であることがわかります。さらに、Unsloth Coreというコードベースの使い方も用意されており、画面で操作したい人と、Pythonなどのコードから使いたい人の両方を意識した設計です。
初心者が最初に理解しておきたいのは、Unsloth Studioが「モデルを作る魔法の箱」ではなく、既存のオープンモデルを実行し、必要に応じて学習や調整をしやすくするための作業環境だということです。たとえば、チャット用途でモデルを試す、手元のデータを使って学習する、モデルを別形式に書き出す、といった流れをまとめて扱う入口になります。公式リポジトリはunslothai/unsloth GitHub repositoryで確認できます。
| 比較項目 | Unsloth Studio | Unsloth Core |
|---|---|---|
| 操作方法 | ブラウザのWeb UI | PythonコードやNotebook |
| 向いている人 | 画面で流れを確認したい初心者 | 学習処理を細かく制御したい人 |
| 主な用途 | 実行、データ準備、学習、監視、書き出し | スクリプト化、再現実験、独自処理への組み込み |
| 最初の選び方 | まずはこちら | Studioで流れを理解してからでもよい |
最初は「ローカルLLM用の作業台」と考えると、かなり理解しやすいです。
Unsloth Studioでできること
Unsloth Studioの中心は、ローカル環境でモデルを動かすことと、モデルを学習することです。GitHubのREADMEでは、検索、ダウンロード、実行に対応するモデル形式としてGGUF、LoRA adapters、safetensorsが挙げられています。これは、モデルを扱うときに出てきやすい形式を、Unsloth Studioの中でまとめて扱える可能性があるという意味です。
また、モデルのエクスポート機能として、GGUFや16-bit safetensorsなどへの保存・書き出しにも触れられています。モデルを一度学習したあと、別の実行環境で使いたい場合、形式の変換は大きな課題になります。Unsloth Studioがこの部分を機能として掲げている点は、実験だけで終わらず、次の利用につなげたい人にとって重要です。
さらに、READMEではツール呼び出し、Web検索、コード実行、API inference endpointにも言及されています。これらは高度な機能ですが、考え方はシンプルです。モデルに文章を返させるだけでなく、外部の処理や開発ツールと組み合わせて動かすための仕組みです。特に、ローカルLLMをClaude CodeやCodex toolsのような開発ツールから使う説明があるため、開発作業に組み込みたい人にも関係があります。
対応する入力の幅も広く、READMEでは画像、音声、PDF、コード、DOCXなどとのチャットに触れられています。ただし、実際にどこまで安定して使えるかは、環境、モデル、ファイル形式、バージョンに左右されます。初心者は、まずテキストチャットの実行から始め、次にPDFや画像などを試す順番が現実的です。
学習よりも、まずダウンロード済みモデルとの会話を簡単に試したい人は、LM Studio入門も比較候補になります。
できることが多いツールほど、最初は「1つだけ成功させる」進め方が大事です。
対応環境と導入方法の考え方

GitHubのREADMEでは、Unsloth StudioはWindows、Linux、WSL、macOSで動作するとされています。2026年6月13日時点では、macOS、Linux、WSL向けのシェル用インストーラと、Windows PowerShell向けのインストーラが公式に案内されています。コマンドは更新される可能性があるため、実行直前に公式Studioガイドで確認してください。
セットアップ後は、外部公開オプションを付けずにローカル起動します。
unsloth studio -p 8888
初心者にとって注意したいのは、AIモデルの実行や学習は、通常の小さなアプリよりも環境依存が強いことです。CPUだけで動く機能もありますが、学習や大きめのモデル実行ではGPU、VRAM、ドライバ、OSの相性が重要になります。READMEでは、CPUはChatとData Recipesで現在サポートされること、NVIDIAではRTX 30/40/50、Blackwell、DGX Spark、Stationなどに触れられています。また、macOSではTraining、MLX、GGUF inferenceがすべてサポートされると説明されています。
環境を汚したくない場合は、Dockerの利用も選択肢になります。READMEではDocker imageとしてunsloth/unslothコンテナが紹介されています。特に、Python、GPU、Jupyter、依存ライブラリが絡む環境は、あとから整理しにくくなりがちです。研究や授業で壊れにくく使いたい場合は、最初からDockerやWSLなど、切り分けしやすい環境を検討すると安全です。
ただし、DockerでGPUを使うには、ホスト側のGPU設定やDocker側のGPU対応が必要です。コマンドをコピーする前に、自分のPCがNVIDIA GPUなのか、macOSなのか、CPU中心なのかを確認しましょう。Unsloth Coreをコードから使う場合は、READMEにuvを使った仮想環境作成とインストール例も掲載されています。画面操作を中心にしたいならStudio、コードで細かく制御したいならCore、という分け方がわかりやすいです。
起動中にOOMやVRAM不足が出た場合は、モデルを小さくする、量子化済みGGUFを選ぶ、コンテキスト長や同時処理を減らす、不要なGPUアプリを終了する順で確認します。学習では推論より多くのメモリが必要になるため、チャットが動いても同じモデルを学習できるとは限りません。
AI系ツールは、最初の環境分離で後日のトラブル量がかなり変わります。
学習機能で注目したいポイント
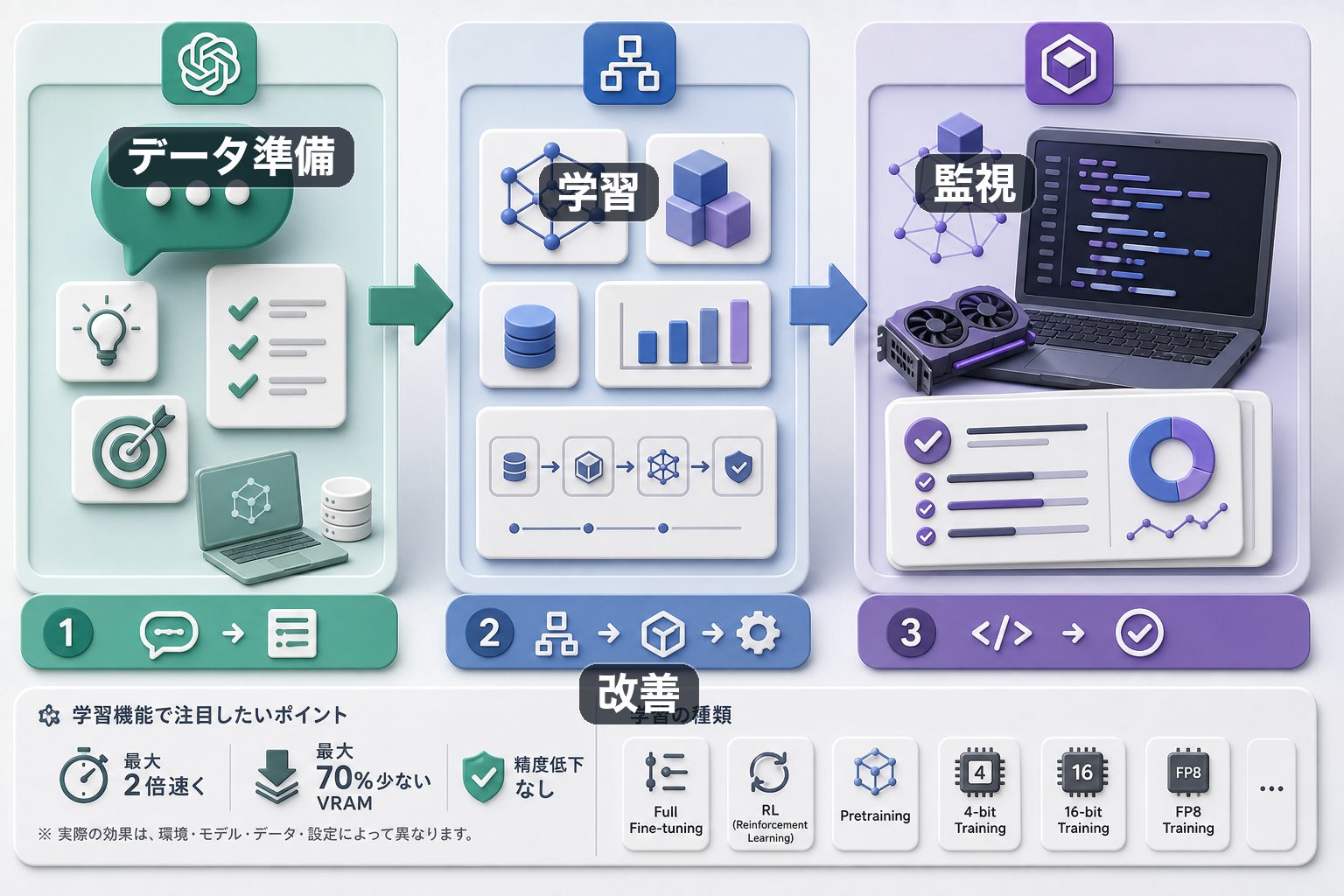
UnslothのREADMEでは、学習機能について「500以上のモデルを最大2倍速く、最大70%少ないVRAMで、精度低下なしにTrain and RLできる」と説明されています。このような性能に関する記述は、実際の環境やモデル、データ、設定によって体感が変わるため、初心者は「必ず自分の環境でも同じ結果になる」と受け取るのではなく、公式が掲げる目標や特徴として理解するのが安全です。
学習の種類としては、full fine-tuning、RL、pretraining、4-bit、16-bit、FP8 trainingが挙げられています。これらの用語は難しく見えますが、ざっくり言えば、モデル全体をしっかり調整する方法、強化学習のような手法、事前学習に近い処理、メモリを節約しながら学習する方法などです。最初から全部を理解する必要はありません。まずは「小さめのモデルを、少量のデータで試す」ことが大切です。
Data Recipesという機能にも注目です。READMEでは、PDF、CSV、DOCXなどからデータセットを自動作成し、visual-node workflowでデータ編集できると説明されています。学習では、モデルそのものよりもデータの品質が結果を左右することが多いです。CSVの列がずれている、PDFから抽出した文章が崩れている、回答例が不自然である、といった問題があると、学習後のモデルも期待通りに動きません。
Observabilityとして、学習をライブで監視し、lossやGPU使用量を追跡し、グラフをカスタマイズできることにも触れられています。これは初心者にとってかなり大切です。学習が進んでいるのか、止まっているのか、GPUメモリが足りないのかを見える形で確認できれば、原因を切り分けやすくなります。学習は一度で成功するものではなく、データ、設定、モデルを少しずつ直していく作業です。
学習は「モデル選び」より先に「データの整え方」で差が出ます。
ローカル実行のメリットと注意点
ローカルでオープンモデルを動かす一番の魅力は、自分の管理できる環境で試せることです。クラウドAPIだけに頼らず、手元のPCや自分で用意したサーバーで動かせると、学習、検証、開発ツール連携を自分のペースで進めやすくなります。Unsloth Studioは、その入口としてWeb UIを提供している点が特徴です。
一方で、ローカル実行には注意点もあります。大きなモデルほどメモリやVRAMを使います。モデル形式、量子化、コンテキスト長、同時実行数などによっても負荷は変わります。READMEではGGUF、LoRA adapters、safetensorsなどの形式が挙げられていますが、どの形式が最適かは用途によります。軽く試したいのか、学習したいのか、他ツールへ持ち出したいのかを決めてから選ぶと迷いにくくなります。
また、API inference endpointにより、ローカルLLMを開発ツールから使う流れも示されています。これは便利ですが、ローカルで起動したサーバーをどこまで公開するかには注意が必要です。READMEでは、クラウドやグローバルアクセス向けに-H 0.0.0.0を追加できると説明されていますが、デフォルトではローカルのみアクセス可能とされています。初心者は、意味がわからないまま外部公開しないことが大切です。
GitHubの説明の通り、Unsloth Studioはローカル利用を強く意識したツールです。ただし、ローカルであるほど、環境の責任も自分側に寄ります。公式README、ドキュメント、現在のOS・GPU条件を確認しながら、段階的に進めましょう。
Unsloth CoreをMacへ直接入れる場合は、依存関係を分離するためにMacで始めるPython venvも確認してください。
便利な公開オプションほど、最初はローカル限定で試すのが堅実です。
初心者におすすめの始め方
最初の目標は、いきなり学習ではなく、Unsloth Studioを起動してモデルを1つ動かすことです。READMEでは、インストール後にunsloth studio -p 8888で起動する例が示されています。ポート番号8888は、ローカルのWeb UIにアクセスするための入口として使われます。ここで画面が開き、モデルを選んで実行できれば、第一段階は成功です。
次に、軽めのモデルや公式が案内しているノートブックを使って、モデルの応答を確認します。モデル名の新しさだけで選ばず、用途、必要メモリ、ライセンス、日本語性能、書き出したい形式を確認してください。初心者は、手元のメモリに余裕がある小さなモデルから始めると、起動エラーとモデル固有の問題を分けやすくなります。
学習を始める場合は、データ量を小さくし、目的を狭くします。たとえば「社内FAQ風の回答を学ばせる」「特定の文体に寄せる」「短い分類タスクを試す」などです。最初から大量のPDFや複雑な会話データを入れると、失敗したときに原因がわかりません。Data Recipesのようなデータ準備機能を使う場合も、まずは少量で中身を確認しましょう。
最後に、結果を残す習慣をつけます。使ったモデル名、データ、学習設定、実行環境、失敗したエラーをメモしておくと、次に改善しやすくなります。AI学習は、同じ操作をしているつもりでも、環境やバージョンで結果が変わることがあります。再現できる形で進めることが、初心者から一歩進むための近道です。
成功ログより、失敗ログを残している人のほうが上達が早いです。
FAQ
Q1. Unsloth Studioは何をするツールですか?
A. GitHubのREADMEでは、Unsloth Studioはローカルでモデルを実行・学習するためのWeb UIとして説明されています。テキスト、音声、埋め込み、ビジョン系モデルへの言及があり、モデルの検索、ダウンロード、実行、エクスポート、学習、監視などの機能が紹介されています。初心者向けに言えば、オープンモデルを手元で試すための操作画面です。
まずは「AIモデル用の管理画面」と考えると入りやすいです。
Q2. Windowsでも使えますか?
A. READMEでは、Unsloth StudioはWindows、Linux、WSL、macOSで動作するとされています。Windows向けにはPowerShellで実行するインストールコマンドが案内されています。ただし、学習やGPU利用では環境依存があるため、Windowsネイティブで進めるか、WSLやDockerを使うかは目的に合わせて選ぶ必要があります。
Windowsでは、まず環境を分けて壊れにくくする考え方が大事です。
Q3. Dockerで使うメリットはありますか?
A. READMEでは、unsloth/unslothというDocker imageが紹介されています。Dockerを使うと、Pythonやライブラリの依存関係をホスト環境から切り分けやすくなります。特にAI学習系は環境が複雑になりやすいため、研究や授業で安定して試したい場合は、Dockerを検討する価値があります。
あとで消しやすい環境は、実験向きです。
Q4. Unsloth Coreとの違いは何ですか?
A. READMEでは、UnslothにはWeb UIのUnsloth Studioと、コードベースのUnsloth Coreがあると説明されています。Studioは画面で操作したい人向け、Coreはコードから細かく扱いたい人向けと考えるとわかりやすいです。初心者はStudioから始め、必要になったらCoreに進む流れが自然です。
画面で流れをつかんでからコードに進むと、理解が速くなります。
Q5. 学習には高性能GPUが必須ですか?
A. READMEでは、CPUはChatとData Recipesで現在サポートされること、NVIDIAやmacOS、AMDに関する対応状況が説明されています。学習や大きなモデルの実行ではGPUやVRAMが重要になりますが、すべての作業で高性能GPUが必須とは限りません。まずは小さな用途から試し、必要に応じて環境を強化するのが現実的です。
最初から最強PCを用意するより、小さく動かして必要条件を知るほうが安全です。
Q6. 外部からアクセスできるようにしても大丈夫ですか?
A. READMEでは、クラウドやグローバルアクセスのために-H 0.0.0.0を追加できると説明されています。一方で、デフォルトではローカルのみアクセス可能とされています。初心者は、セキュリティの意味を理解しないまま外部公開しないほうが安全です。まずはローカル環境だけで動作確認を行いましょう。
公開設定は便利ですが、理解してから使う項目です。
まとめ
Unsloth Studioは、オープンモデルをローカルで実行し、必要に応じて学習まで進めたい人にとって注目しやすいWeb UIです。GitHubのREADMEでは、Windows、Linux、WSL、macOSへの対応、モデルの実行、エクスポート、ツール呼び出し、API inference endpoint、学習監視、Data Recipesなど、幅広い機能が紹介されています。
初心者は、まずUnsloth Studioを起動し、小さなモデルを動かすところから始めるのがおすすめです。その後、データを少量用意して学習を試し、必要に応じてDockerやUnsloth Coreを検討すると、環境を壊しにくく、学びやすい進め方になります。
Unsloth Studioは、ローカルAI開発の入口として非常に実用的です。大切なのは、一度にすべてを使おうとしないことです。実行、確認、記録、改善を小さく回していけば、ローカルLLMの理解は着実に深まります。
学習したモデルを複数人向けのチャット画面へ接続したい場合は、LibreChatの使い方も次の候補です。
AIツールは派手に見えますが、結局は小さな成功を積み上げるのが一番強いです。


コメント